回溯算法
回溯算法是一种通过系统性试探和回退策略搜索问题解的通用方法,适用于组合优化、约束满足等复杂问题,其核心特征是“能进则进,不进则退”的深度优先搜索机制。
参考文章:
回溯算法详解
概念
回溯算法,又称为“试探法”。是一种选优搜索法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为“回溯点”。许多复杂的,规模较大的问题都可以使用回溯法,有“通用解题方法”的美称。
基本思想
基本思想:从一条路往前走,能进则进,不能进则退回来,换一条路再试。
八皇后问题就是回溯算法的典型,第一步按照顺序放一个皇后,然后第二步符合要求放第2个皇后,如果没有位置符合要求,那么就要改变第一个皇后的位置,重新放第2个皇后的位置,直到找到符合条件的位置就可以了。回溯在迷宫搜索中使用很常见,就是这条路走不通,然后返回前一个路口,继续下一条路。回溯算法说白了就是穷举法。不过回溯算法使用剪枝函数,剪去一些不可能到达 最终状态(即答案状态)的节点,从而减少状态空间树节点的生成。
回溯算法求解问题时,按深度优先搜索策略对解空间树进行搜索,在搜索至解空间树中的任一结点时,先判断该结点是否包含问题的解:
- 若包含问题的解,则沿着该分支继续进行深度优先搜索遍历;
- 否则,跳过该结点的分支沿着该结点向上一个结点回溯。
回溯法在用来求问题的所有解时,要回溯到根,且根结点的所有子树都已被搜索遍才结束。而回溯法在用来求问题的任一解时,只要搜索到问题的一个解就可以结束。这种以深度优先的方式系统地搜索问题的解的算法称为回溯法,它适用于解一些组合数较大的问题。
深度优先遍历(DFS)
深度优先遍历算法采用了回溯思想,从起始节点开始,沿着一条路径尽可能深入地访问节点,直到无法继续前进时为止,然后回溯到上一个未访问的节点,继续深入搜索,直到完成整个搜索过程。
因为遍历到的节点顺序符合「先进后出」的特点,所以深度优先搜索遍历可以通过「栈/递归」来实现。
特点:一路到底,逐层回退。
用途:解决找到所有解问题(找到起始–终点的所有路径,此时 DFS 空间占用少)。
例题参见 算法题二(二叉树)
广度优先遍历(BFS)
广度优先遍历是一种由近及远的遍历方式,从某个节点出发,始终优先访问距离最近的顶点,并一层层向外扩张。以此类推,直到完成整个搜索过程。
因为遍历到的节点顺序符合「先进先出」的特点,所以广度优先遍历可以通过「队列」来实现。
特点:全面扩散,逐层递进。
用途:解决找到最优解的问题(找到的第一个起始–终点路径,即是最短路径)。
例题参见 算法题三
回溯VS递归
在回溯法中可以看到有递归的身影,但两者有区别。 回溯法从问题本身出发,寻找可能实现的所有情况。和穷举法的思想相近,不同在于穷举法是将所有的情况都列举出来以后再一一筛选,而回溯法在列举过程如果发现当前情况根本不可能存在,就停止后续的所有工作,返回上一步进行新的尝试。
递归是从问题的结果出发,例如求 n!,要想知道 n!的结果,就需要知道 n*(n-1)! 的结果,而要想知道 (n-1)! 结果,就需要提前知道 (n-1)*(n-2)!。这样不断地向自己提问,不断地调用自己的思想就是递归。
回溯和递归唯一的联系就是,回溯法可以用递归思想实现。
回溯算法的实现过程
使用回溯法解决问题的过程,实际上是建立一棵“状态树”的过程。例如,在解决列举集合{1,2,3}所有子集的问题中,对于每个元素,都有两种状态,取还是舍,所以构建的状态树为:
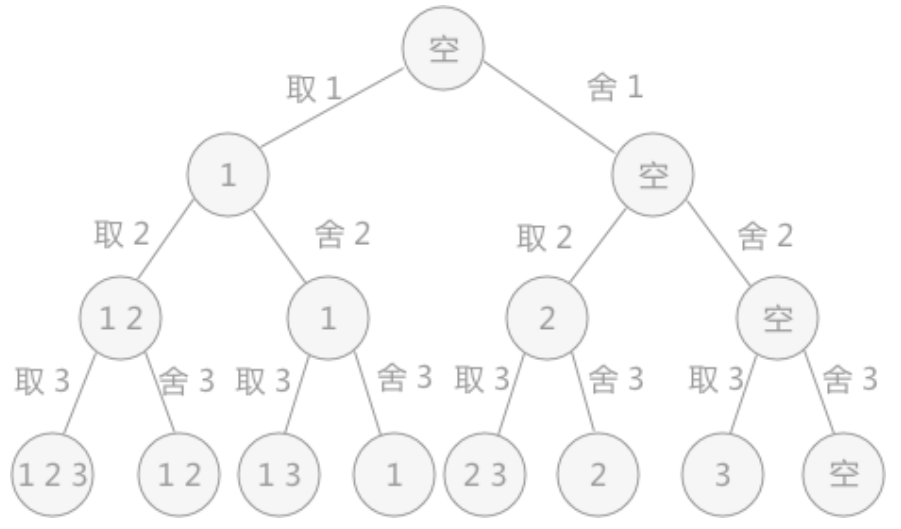
回溯算法的求解过程实质上是先序遍历“状态树”的过程。树中每一个叶子结点,都有可能是问题的答案。图中的状态树是满二叉树,得到的叶子结点全部都是问题的解。
在某些情况下,回溯算法解决问题的过程中创建的状态树并不都是满二叉树,因为在试探的过程中,有时会发现此种情况下,再往下进行没有意义,所以会放弃这条死路,回溯到上一步。在树中的体现,就是在树的最后一层不是满的,即不是满二叉树,需要自己判断哪些叶子结点代表的是正确的结果。
算法思路
用回溯算法解决问题的一般步骤:
- 针对所给问题,定义问题的解空间,它至少包含问题的一个(最优)解。
- 确定易于搜索的解空间结构,使得能用回溯法方便地搜索整个解空间 。
- 以深度优先的方式搜索解空间,并且在搜索过程中用剪枝函数避免无效搜索。
问题的解空间
问题的解空间至少包含一个最优解。例如,对于装载问题,若有 n 个集装箱要装上一艘载重量为 c 的轮船,其中集装箱 i 的重量为 wi,要求在不超过轮船载重量的前提下,将尽可能多的集装箱装上轮船。
当 n=3 时,解空间是由长度为 3 的向量组成的,每个向量的元素取值为 0 或 1,解空间为:
1 | {(0,0,0),(0,0,1),(0,1,0),(1,0,0),(0,1,1),(1,0,1),(1,1,0),(1,1,1)} |
其中,0 表示不装入轮船,1 表示装入轮船。若 c=50,W={18, 25, 25},则解空间可用一棵二叉树表示,左分支用 1 表示,右分支用 0 表示,如下图所示。其中,解向量 (1,1,1) 表示将重量为 18、25、25 的集装箱都装入轮船,总重量为 68。解向量 (0,1,1) 表示将重量为 25 和 25 的集装箱装入轮船,总重量为 50。
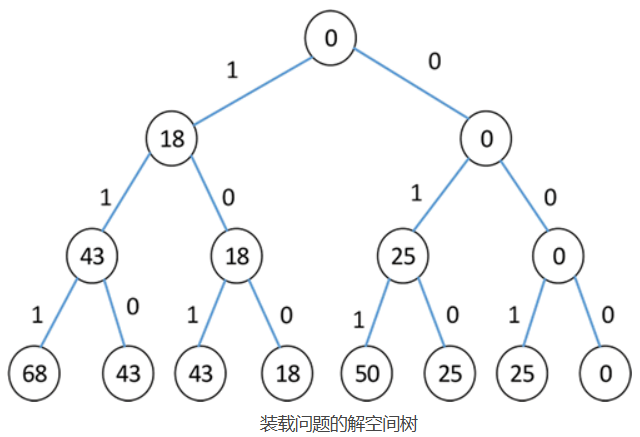
解空间树一般分为两种:子集树和排列树。当所给的问题是从 n 个元素的集合 S 中找出满足某种性质的子集时,相应的解空间树称为子集树。当所给问题是确定 n 个元素满足某种性质的排列时,相应的解空间树称为排列树。排列树通常有 n! 个叶子结点。因此,遍历排列树需要 O(n!) 的计算时间。
算法的基本思想
在构造好解空间树之后,可以利用回溯算法对解空间树进行搜索,通过搜索求出问题的最优解。从解空间树的根结点出发,对解空间进行深度优先搜索遍历:
- 初始时,根结点成为活结点,并成为当前的扩展结点,沿着扩展结点向纵深方向搜索,达到一个新的结点后,新的结点就成为活结点,并成为当前的扩展结点。
- 若当前的扩展结点不能继续向前搜索,则当前的扩展结点成为死结点,这时就会回溯到最近的活结点位置。
- 重复按以上方式搜索整个解空间树,直到程序结束。
若已经生成一个结点或多个结点,而它的所有孩子结点还没有全部生成,则该结点称为活结点;扩展结点指的是当前正在生成孩子结点的活结点;死结点指的是不再继续扩展的结点或其孩子结点已经全部生成的结点。
贪心算法实际应用
解决装载问题
已知有 n 个集装箱(重量分别为 w1,w2,…,wn)和 1 艘轮船,轮船的载重量为 c,要求在不超过轮船载重量的前提下,将尽可能多的集装箱装入轮船。其中,第 i 个集装箱的重量为 wi。
当 c=50、W={18, 25, 25} 时,装载问题的搜索过程可以表示成一棵子集树,如下图所示:
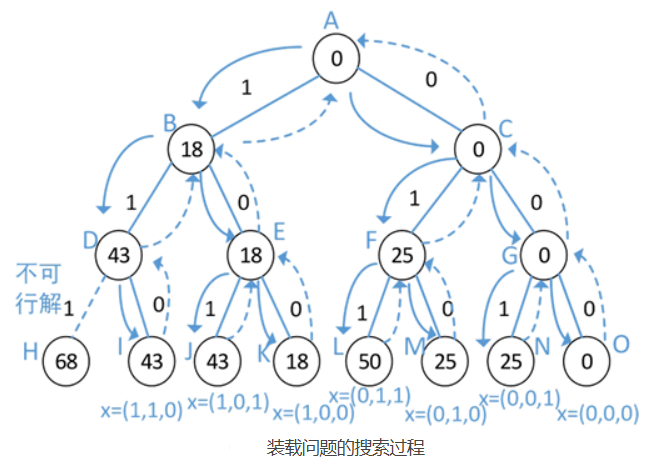
初始时,根结点是唯一的活结点,也是当前的扩展结点,此时轮船的剩余容量为 cr=50,还未有集装箱装入轮船。
从根结点 A 出发对左分支结点 B 进行扩展,若将第 1 个集装箱装入轮船,则有 cr=50-18=32,此时结点 B 为当前的扩展结点,结点 A 和结点 B 为活结点。
从当前的扩展结点 B 继续沿深度方向扩展,若将第 2 个集装箱装入轮船,则有 cr=32-25=7,此时结点 D 为当前的扩展结点,结点 A、结点 B 和结点 D 为活结点。
从当前的扩展结点 D 沿着左分支继续扩展,由于 cr<25,因此无法将第 3 个集装箱放入轮船,这是一个不可行的解,回溯到结点 D。
结点 D 成为活结点,并成为当前的扩展结点,从结点 D 沿着右分支进行扩展,扩展到结点 I,即不将第 3 个集装箱装入轮船,此时有第 1 个和第 2 个集装箱装入轮船,得到一个可行解,解向量为 {1,1,0},装入轮船的集装箱总重量为 43。
结点 I 不能再扩展,成为死结点,回溯到结点 D,结点 D 已无可扩展结点,成为死结点,回溯到结点 B。
结点 B 成为当前的扩展结点,沿着结点 B 向右分支结点扩展,到达结点 E,结点 E 成为活结点,并成为当前的扩展结点,第 2 个集装箱不装入轮船,此时轮船上只有第 1 个集装箱,cr=32。
沿着结点 E 往左分支扩展,结点 J 成为活结点,并成为当前的扩展结点,将第 3 个集装箱装入轮船,此时有 cr=32-25=7,第 1 个和第 3 个集装箱装入轮船,解向量为 {1,0,1},装入轮船的总重量为 43。
结点 J 不可扩展,成为死结点,回溯到结点 E,结点 E 成为当前的扩展结点,沿着结点 E 向右分支扩展,到达结点 K,结点 K 为活结点,即第 3 个集装箱不装入轮船,此时 cr=32,只有第 1 个集装箱装入轮船,解向量为 {1,0,0},装入轮船的总重量为 18。
按照以上方式继续在解空间树上搜索,搜索完毕后,即可得到装载问题的最优解,最优解为 {0,1,1}。
解决旅行商问题
旅行商问题(Traveling Salesman Problem,TSP)又称为旅行推销员问题、货郎担问题,是数学领域的著名问题之一。
一个旅行商要从 n 个城市的某一城市出发去往其他城市,每个城市经过且只经过一次,最后回到原来出发的城市。求在去往任何一个城市的所有路径中路径长度最短的一条。
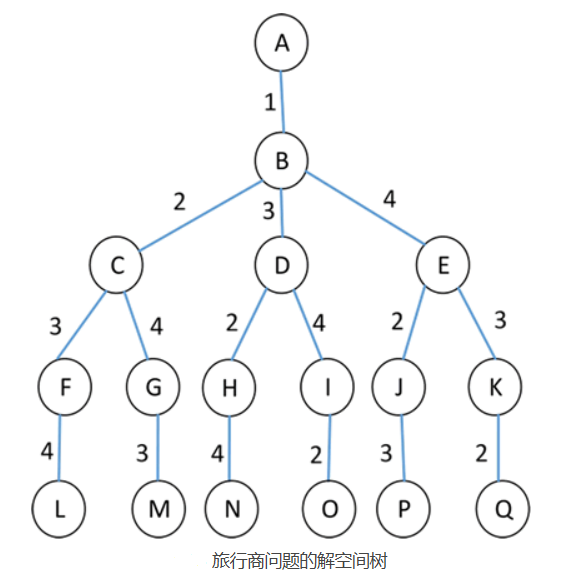
为了方便描述该问题,可采用带权图表示 n 个城市之间的关系,顶点表示城市,顶点之间的权值表示城市之间的距离。例如,n=4 时的旅行商问题可用下图表示。
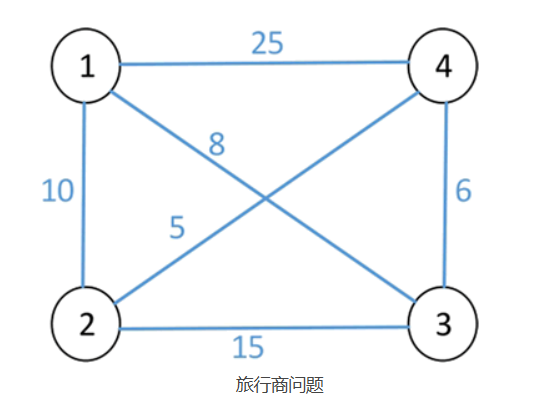
图中的回路有 (1,2,3,4,1)、(1,2,4,3,1)、(1,3,2,4,1)、(1,4,2,3,1)、(1,3,4,2,1) 等,其中 (1,3,4,2,1) 的路径长度最短,其路径长度为 29。旅行商人所走过的可能路线其实是所有路径的排列组合,这些方案可绘制成一棵排列树,也是该问题的解空间树,如下图所示。该树的深度为 5,两个结点之间的路径表示旅行商经过的城市。
算法题一
N 皇后
题目链接:LeetCode_51. N 皇后
问题描述:
按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。
n 皇后问题 研究的是如何将n个皇后放置在n×n的棋盘上,并且使皇后彼此之间不能相互攻击。给你一个整数n,返回所有不同的 n 皇后问题 的解决方案。
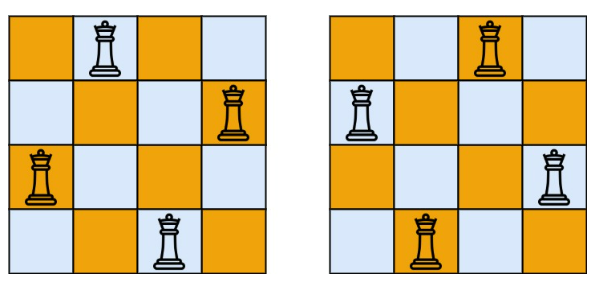
每一种解法包含一个不同的 n 皇后问题 的棋子放置方案,该方案中'Q'和'.'分别代表了皇后和空位。示例 1
输入:n = 4
输出:[[“.Q..”,”…Q”,”Q…”,”..Q.”],[“..Q.”,”Q…”,”…Q”,”.Q..”]]
解释:如上图所示,4 皇后问题存在两个不同的解法。示例 2:
输入:n = 1
输出:[[“Q”]]提示:
1 <= n <= 9解释:n皇后和数独有异曲同工的方法。数独是每个横竖宫只有一个相同数字,皇后是横竖斜只有一个皇后。所以N*N矩阵皇后每行每列只有一个皇后。
判断皇后位置正确:判断某位置是否可以放下皇后时,由于是从左往右从上往下的遍历顺序,因此只需要检索当前点的上方,左上方,右上方即可。此外,由于回溯内部的for循环是从左往右遍历的,所以可以肯定遍历到当前节点的时候,当前节点的左边肯定没有皇后, 因此可以不对左边节点进行检索
1 | List<List<String>> res = new ArrayList<>(); // 结果集 |
电话号码的字母组合
问题描述:
给定一个仅包含数字
2-9的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。给出数字到字母的映射与电话按键相同。注意 1 不对应任何字母。示例 1:
2
输出:["ad","ae","af","bd","be","bf","cd","ce","cf"]示例 2:
2
输出:[]示例 3:
2
输出:["a","b","c"]提示:
0 <= digits.length <= 4digits[i]是范围['2', '9']的一个数字。
1 | List<String> re = new ArrayList<>(); // 结果集 |
算法题二(二叉树)
树节点定义
1 | // Definition for a binary tree node. |
二叉树遍历
1 | // 先序遍历 父 左 右 |
二叉树还原
公共代码块
1 | public static void main(String[] args) { |
已知:后序 + 中序
案例:
后序 : C B E F D A
中序 : C B A E D F
- 后序 最后一个元素 A 为根节点
- 在中序中左子树在根节点左侧:拿着根节点 A 在中序中找
- 对照着后序:CB 为左子树的后序,EFD 为右子树的后序
- 还原 A 的左子树
后序 CB 确定 B 为左子树的根节点,拿着 B 去中序中找,C 是 B 的左子树,B 的右子树为空 中序 CB- 还原 A 的右子树
后序 EFD D 为右子树的根 中序 EDF D 的左子树是 E 右子树为 F
1 | public static TreeNode buildTree(char[] charsMid, char[] charsEnd) { |
已知:先序 + 中序
案例:
先序 : E F H I G J K
中序 : H F I E J K G
- 先序 第一个元素 E 为根节点
- 在中序中左子树在根节点左侧:拿着根节点 E 在中序中找
- 对照着先序:FHI 为左子树的先序,GJK 为右子树的先序
- 还原 E 的左子树
先序 FHI 确定 F 为左子树的根节点,拿着 F 去中序中找,H 是 F 的左子树,I 为 F 的右子树 中序 HFI- 还原 E 的右子树
先序 GJK G 为右子树的根 中序 JKG G 的左子树是 JK 右子树为空- 还原G的左子树
先序 JK J 为 G 的左子树的根 中序 JK J 为 G 的左子树的右子树
1 | public static TreeNode buildTree(char[] charsMid, char[] charsPre) { |
二叉树的直径
题目链接:LeetCode_543. 二叉树的直径
问题描述:
给你一棵二叉树的根节点,返回该树的 直径 。二叉树的 直径 是指树中任意两个节点之间最长路径的 长度 。这条路径可能经过也可能不经过根节点root。两节点之间路径的 长度 由它们之间边数表示。示例 1:
2
3
输出:3
解释:3 ,取路径 [4,2,1,3] 或 [5,2,1,3] 的长度。示例 2:
2
输出:1提示:
- 树中节点数目在范围
[1, 10^4]内-100 <= Node.val <= 100
1 | int max = 0; // 全局变量 最长路径 |
二叉树中的最大路径和
问题描述:
二叉树中的 路径 被定义为一条节点序列,序列中每对相邻节点之间都存在一条边。同一节点在一条路径序列中 至多出现一次 。该路径 至少包含一个节点,且不一定经过根节点。 路径和是路径中各节点值的总和。给出二叉树的根节点root,返回其最大路径和 。示例 1:
2
3
输出:6
解释:最优路径是 2 -> 1 -> 3 ,路径和为 2 + 1 + 3 = 6示例 2:
2
3
输出:42
解释:最优路径是 15 -> 20 -> 7 ,路径和为 15 + 20 + 7 = 42提示:
- 树中节点数目范围是
[1, 3 * 104]-1000 <= Node.val <= 1000
1 | int res = Integer.MIN_VALUE; // 全局变量 最大路径和 |
相邻字符不同的最长路径
题目链接:LeetCode_2246. 相邻字符不同的最长路径
问题描述:
给你一棵 树(即一个连通、无向、无环图),根节点是节点0,这棵树由编号从0到n - 1的n个节点组成。用下标从 0 开始、长度为n的数组parent来表示这棵树,其中parent[i]是节点i的父节点,由于节点0是根节点,所以parent[0] == -1。
另给你一个字符串s,长度也是n,其中s[i]表示分配给节点i的字符。
请你找出路径上任意一对相邻节点都没有分配到相同字符的 最长路径 ,并返回该路径的长度。
示例 1:
2
3
4
输出:3
解释:任意一对相邻节点字符都不同的最长路径是:0 -> 1 -> 3 。该路径的长度是 3 ,所以返回 3 。
可以证明不存在满足上述条件且比 3 更长的路径。示例 2:
2
3
输出:3
解释:任意一对相邻节点字符都不同的最长路径是:2 -> 0 -> 3 。该路径的长度为 3 ,所以返回 3 。
提示:
n == parent.length == s.length1 <= n <= 10^5- 对所有
i >= 1,0 <= parent[i] <= n - 1均成立parent[0] == -1parent表示一棵有效的树s仅由小写英文字母组成
1 | List<List<Integer>> adj = new ArrayList<>(); |
最长同值路径
题目链接:LeetCode_687. 最长同值路径
问题描述:
给定一个二叉树的root,返回 最长的路径的长度 ,这个路径中的 每个节点具有相同值 。 这条路径可以经过也可以不经过根节点。两个节点之间的路径长度 由它们之间的边数表示。示例 1:
2
输出:2示例 2:
2
输出:2提示:
- 树的节点数的范围是
[0, 10^4]-1000 <= Node.val <= 1000- 树的深度将不超过
1000思路:对于任意一个节点, 如果最长同值路径包含该节点, 那么只可能是两种情况:
1. 其左右子树中加上该节点后所构成的同值路径中较长的那个继续向父节点回溯构成最长同值路径 2. 左右子树加上该节点都在最长同值路径中, 构成了最终的最长同值路径需要注意因为要求同值, 所以在判断左右子树能构成的同值路径时要加入当前节点的值作为判断依据
1 | private int maxL = 0; |
算法题三
流浪地球
问题描述:
流浪地球计划在赤道上均匀部署了N个转向发动机,按位置顺序编号为0~N。
- 初始状态下所有的发动机都是未启动状态;
- 发动机启动的方式分为”手动启动”和”关联启动”两种方式;
- 如果在时刻1一个发动机被启动,下一个时刻2与之相邻的两个发动机就会被”关联启动”;
- 如果准备启动某个发动机时,它已经被启动了,则什么都不用做
发动机0与发动机N-1是相邻的。地球联合政府准备挑选某些发动机在某些时刻进行“手动启动”。当然最终所有的发动机都会被启动。
哪些发动机最晚被启动呢?输入描述:第一行两个数字N和E,中间有空格,N代表部署发动机的总个数,E代表计划手动启动的发动机总个数 1<N<=1000,1<=E<=1000,E<=N。接下来共E行,每行都是两个数字T和P,中间有空格 T 代表发动机的手动启动时刻,P代表此发动机的位置编号。 0<=T<=N.0<=P<N
输出描述:第一行一个数字N,以回车结束 N代表最后被启动的发动机个数;第二行N个数字,中间有空格,以回车结束 每个数字代表发动机的位置编号,从小到大排序示例 1:
2
3
4
5
6
7
8 2
0 2
0 6
输出
2
0 4说明:
2
3
4
5
时刻0启动(2,6);
时刻1启动(1,3.5,7)(其中1,3被2关联启动,5,7被6关联启动);
时刻2启动(0,4)(其中0被1,7关联启动,4被3,5关联启动);
至此所有发动机都被启动,最后被启动的有2个,分别是0和4。思路:模拟。枚举每一秒时间,用一个队列维护当前启动了哪些发动机。之后每一秒先遍历队列中的所有发动机,尝试向左右两侧扩展一次,如果扩展到没有启动的发动机就更新其启动时间,同时把发动机放入队列。之后再遍历所有手动启动的发动机,如果某个发动机没启动并且会在这一秒启动,就把他放入队列同时更新启动时间这样就能更新出所有发动机的最早启动时间,找出最大值并输出所有最晚启动的即可。
1 | public static void problem28(int n, List<int[]> a) { |
Boss的收入
问题描述:
一个XX产品行销总公司,只有一个boss,其有若干一级分销,一级分销又有若干二级分销,每个分销只有唯一的上级分销。规定每个月,下级分销需要将自己的总收入(自己的+下级上交的)每满100元上交15元给自己的上级。现给出一组分销的关系,和每个分销的收入,请找出 boss并计算出这 boss 的收入。
比如:收入100元上交15元,收入199元(9元不够100)上交15元,收入200元,上交30元。
分销关系和收入:分销id 上级分销的id 收入;分销ID范围0…65535 ;收入范围:0…65535,单位元
提示:输入的数据只存在1个 boss,不存在环路
输入描述:第1行输入关系的总数量N;第2行开始,输入关系信息,格式:分销ID 上级分销ID 收入
输出描述:boss的ID 总收入
补充说明:给定的输入数据都是合法的,不存在重复示例 1:
2
3
4
5
6
7
8
5
1 0 100
2 0 200
3 0 300
4 0 200
5 0 200
输出 0 150示例 2:
2
3
4
5
6
7
3
1 0 223
2 0 323
3 2 1203
输出 0 105
说明:2的最终收入等于323+1203/100*15=323+180;0的最终收入等于(323+180+223)/100*15=105思路:使用一个队列进行广度优先搜索(BFS)。从队列中取出当前分销IDx,获取其上级分销IDy,更新收入并更新上级分销的下级计数器in。如果某个上级分销没有下级分销了,将其加入队列。重复此过程直至队列为空。
1 | // 关系的总数量N, 关系信息列表(分销ID 上级分销ID 收入) |




