业务相关问题
关于 java 中常见业务问题的一些处理,如微服务日志联调、大批量数据处理的一些记录
微服务日志怎么联通
痛点
- 进程内的多条日志无法追踪。一个请求调用,假设会调用后端十几个方法,打印十几次日志,无法将这些日志串联起来。
- 跨服务的日志如何进行关联。每个微服务都会记录自己这个进程的日志,跨进程的日志如何进行关联?
- 跨线程的日志如何关联。主线程和子线程的日志如何关联?
- 第三方调用我们的服务,如何追踪?
本文针对第一个和第二个问题,稍作描述。
解决方案
- 使用
Skywalking traceId进行链路追踪 - 使用
Elastic APM的 traceId 进行链路追踪 - MDC 方案:自己生成 traceId 并
put到 MDC 里面。
MDC 方案:MDC(Mapped Diagnostic Context)用于存储运行上下文的特定线程的上下文数据。因此,若使用 log4j 进行日志记录,则每个线程都可拥有自己的MDC,该 MDC 对整个线程是全局的。属于该线程的任何代码都可以轻松访问线程的 MDC 中存在的值。
追踪一个请求的多条日志
在
logback日志配置文件中的日志格式中添加%X{traceId}配置。1
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %X{traceId} %-5level %logger - %msg%n</pattern>
自定义拦截器,从请求的
header中获取traceId,若存在则放到MDC中,否则直接用UUID当做 traceId,再放到 MDC 中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public class LogInterceptor extends HandlerInterceptorAdapter {
private static final String TRACE_ID = "traceId";
public boolean preHandle(HttpServletRequest request, HttpServletResponse response,
Object handler) throws Exception {
String traceId = request.getHeader(TRACE_ID);
if (StringUtils.isEmpty(traceId)) {
MDC.put("traceId", UUID.randomUUID().toString());
} else {
MDC.put(TRACE_ID, traceId);
}
return true;
}
public void postHandle(HttpServletRequest request, HttpServletResponse response,
Object handler, ModelAndView modelAndView) throws Exception {
// 防止内存泄露
MDC.remove("traceId");
}
}配置拦截器。
1
2
3
4
5
6
7
8
9
10
11
public class InterceptorConfig implements WebMvcConfigurer {
private LogInterceptor logInterceptor;
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(logInterceptor).addPathPatterns("/**");
}
}
结果:当我们打印日志的时候,会自动打印 traceId,即多条日志的 traceId 相同。
跨服务跟踪多条日志
订单服务远程调用优惠券服务,需要在订单服务中添加 OpenFeign 的拦截器,拦截器里面做的事就是往请求的 header 中添加 traceId,这样调用到优惠券服务时,就能从 header 中拿到这次请求的 traceId。代码如下所示:
1 |
|
结果:两个微服务打印的日志中,两条日志的 traceId 一致。
这些日志都会导入到 Elasticsearch 中的,然后通过 kibana 可视化界面搜索 traceId,就可以将整个调用链路串起来了!
参考链接:微服务中的日志链路追踪
大批量数据导入
前端大批量数据导入数据库
前端处理:用 element plus 的 el-upload 组件来完成文件上传的前端开发。
后端处理:用 springboot 完成文件上传的后台处理逻辑(接收文件、读取文件、文件入库等),从这几个环节考虑提升入库效率,如多线程处理。
在 application.properties 中修改默认限制:spring.servlet.multipart.max-file-size 设置单个文件上传的大小限制,spring.servlet.multipart.max-request-size 设置整个请求(包括所有文件和表单数据)的大小限制。
方案
- 1、每读取一行数据就插入到数据库,每次都要和数据库通信,非常耗时
- 2、考虑批量插入来提高效率,使用 script 来实现数据的批量插入。
- 3、在 controller 中使用多线程来将数据批量插入数据库。
首先要考虑锁和并发的问题。加锁会降低并发性,故使用生产者/消费者模式,读取文件作为生产,多线程进行消费。
两种技术选型,一个是并发队列 ConcurrentLinkedQueue,一个是 disruptor。这两种队列内部都是基于 CAS + voilatile 实现的。性能上 disruptor 略优于 ConcurrentLinkedQueue,但 disruptor 代码量多一些,以 ConcurrentLinkedQueue 为例。
示例代码:
1 | ConcurrentLinkedQueue String, queue = new concurrentLinkedQueue(); |
前端大批量(百万级)数据导入数据库
性能瓶颈分析:一般大数据量 excel 入库场景中,耗时大概在如下几点:
耗时1:读取,字段数量,sheet 页个数,文件体积;选择分片读取及合适的集合存储
耗时2:数据校验,逐行分字段校验;耗时会随字段个数逐渐增加
耗时3:写入,如 Mybatis-plus 的分批插入,采用多线程处理等
针对耗时1进行优化
针对百万级数据的读取,要选择分片读取,分片处理,
实现 EasyExcel 的 ReadListener 页面读取监听器,
实现 invoke 方法,增加 BATCH_COUNT(单次读取条数)配置。单批次BATCH COUNT改为10万
读取完后,选择合适的集合容器( ArrayList)存放临时数据。
1 |
|
针对耗时3进行优化:JDBC分批插入+手动事务控制
通过 PreparedStatement 的 addBatch() 和 executeBatch() 实现JDBC分批插入
1 | // jdbc+事务处理 |
针对耗时3进行优化:多线程+Mybatis-Plus批量插入
Mybatis-Plus 的 IService 提供了 saveBatch 方法,但其仍是循环调用 INSERT INTO
要实现真正批量插入:用 Mybatis-Plus 注入器增强批量插入、手写 xml 拼接 SQL。
建议用注入器(自定义 SQL 注入器实现 DefaultSqlInjector,添加 InsertBatchSomeColumn 方法批量插入。)
1 | // 采用多线程读取数据 |
幂等性问题
参考原文:
幂等(idempotent)是一个数学与计算机学概念,常见于抽象代数中。
在开发过程中,保证幂等性就是保证程序的无论执行多少次,影响均与第一次执行的影响是一致的,产生的结果也是一样的。而幂等函数(幂等方法),是指使用相同的参数结构重复执行,产生相同的结果的函数,重复执行幂等函数不会影响系统的状态或者造成改变。
常见幂等性问题
典型的违反幂等原则导致的问题,如:
- 订单处理场景
订单创建:用户提交订单时,可能因网络问题导致请求重复发送,系统需确保同一订单号只创建一次,避免生成多个相同订单。
订单状态变更:订单状态从”待支付”变更为”已支付”,若客户端重复发送状态变更请求,系统需要保证只变更一次,避免状态不一致。
- 库存扣件场景
高并发抢购:在秒杀、抢购活动中,大量用户同时发起库存扣减请求,系统需保证同一个商品库存只被扣减一次,避免超卖。
分布式库存扣减:在分布式系统中,多个服务节点可能同时处理同一商品的库存扣减请求,需通过幂等设计保证数据一致性。
- 支付与退款场景
支付重复提交:用户在网络波动或前端响应延迟等情况下,可能多次点击支付按钮,导致同一笔订单被多次扣款。
退款操作:在退款接口中,若客户端因超时未收到响应而重试,或恶意用户利用漏洞重复提交退款请求,导致商家资金损失。
- 消息队列场景
消息重复投递:在消息队列中,消息可能因网络问题或消费处理失败而被重复投递。
消息重复消费:消费者在处理消息后,未正确发送确认信号,导致消息被重新投递,系统需要确保消息只被处理一次。
幂等性目标
- 同一请求多次执行 -> 系统状态始终一致
- 不同请求 -> 系统正常处理差异
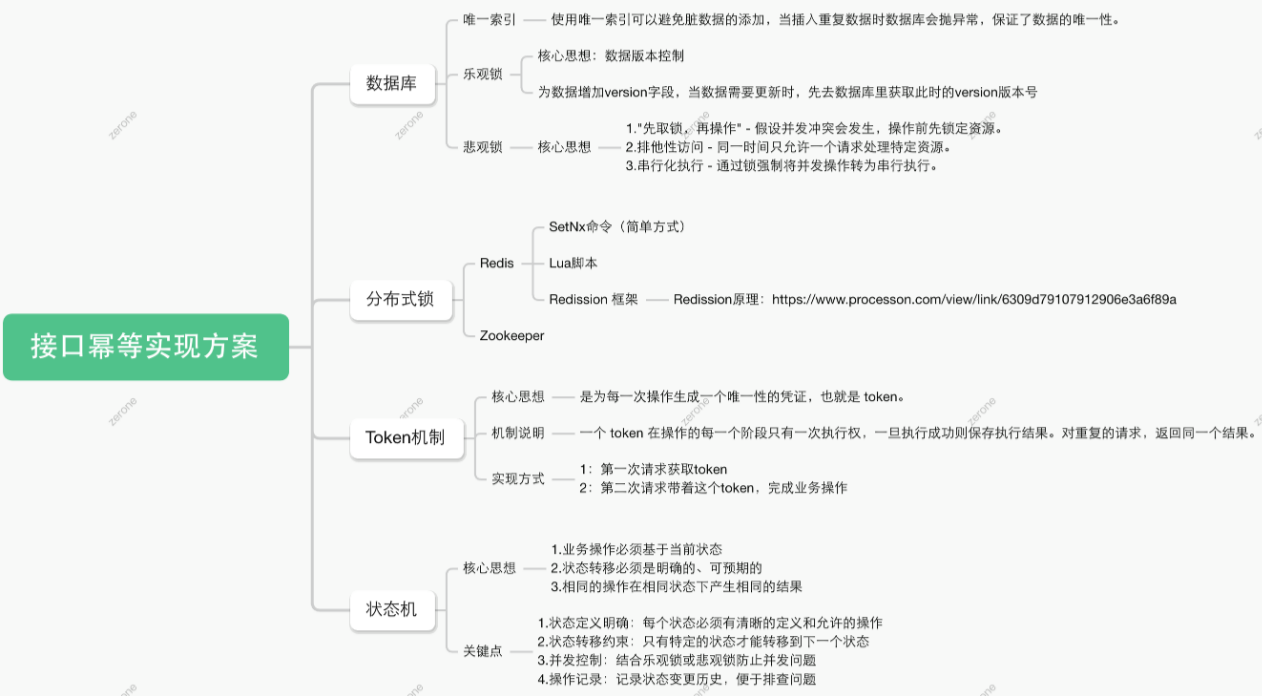
常见的7种解决方案
方案1: Token令牌机制(防重复提交)
原理:Redis创建Token,客户端先获取唯一Token,后续请求携带Token,服务端校验是否已被使用。
适用场景:订单创建、表单提交等插入类操作。
方案2: 唯一ID + 去重表(防重复处理)
原理:为每次请求生成唯一ID(如UUID、雪花算法生成的ID),请求前查询去重表,若存在则直接返回。
适用场景:支付回调、订单状态变更等更新类操作
实现要点:
使用雪花算法生成分布式唯一ID(唯一ID生成方式较多,选择一种即可)
数据库建立唯一索引保证原子性
缺点:
- 需要额外的数据库操作,影响性能
- 防重表可能成为性能瓶颈,需要合理设计索引和分片
方案3: 唯一索引或唯一组合索引
原理:唯一索引或唯一组合索引来防止新增数据出现脏数据(当表存在唯一索引,并发执行时,先进入的执行成功,后进入的会执行失败,说明该数据已经存在了,返回结果即可)。
适用场景:订单创建、注册、会议室抢订等插入类操作,避免插入同样信息的脏数据。
典型案例:中秋节到了,淘宝上线某款限量版的月饼,每个用户都只能购买一盒月饼,如何防止用户被创建多条月饼订单数据,可以给月饼销售表中的用户ID加唯一索引,保证一个用户只能创建成功一条月饼订单记录。
方案4: 乐观锁(读多写少场景)
原理:通过版本号控制更新,仅当数据版本与当前请求版本一致时执行操作(CAS)。
适用场景:账户余额更新、库存扣减等
方案5: 状态机
原理:定义状态转移规则,确保操作只能合法状态跳转。
适用场景:订单生命周期管理(如:已支付 -> 已发货)
典型案例:在设计单据相关业务,或者任务相关业务时,肯定会涉及到状态机(状态变更),就是业务单据上面有个状态,状态在不同情况下会发生变更,一般情况下存在有限状态机。这时候,如果状态机已经处于下一个状态,这时候来了一个上一个的变更,理论上是不能够变更的,保证了有限状态机的幂等。
注意:订单等单据类业务,存在很长的状态流程,一定要深刻理解状态机,对业务系统设计能力提高有很大帮助。
方案6: 分布式锁(强一致性要求)
原理:通过Redis或Zookeeper或MySql唯一索引等实现互斥锁,确保同一时间仅处理一个请求。
使用场景:超卖保护、秒杀库存扣减。
说明:MySql唯一索引存在一定的性能上线,高并发场景下基本不使用
方案7: 前后端双重校验
原理:前端防抖(如按钮置灰或者浮起旋转框)+ 后段唯一ID校验
适用场景:低并发场景快速实现(如用户注册等)
方案对比和选型参考
| 方案 | 性能 | 复杂度 | 适用场景 |
|---|---|---|---|
| Token机制 | 高 | 低 | 插入类操作(如:订单创建等) |
| 唯一ID + 去重表 | 中 | 中 | 更新类操作(如:状态变更等) |
| 唯一索引/唯一组合索引 | 中 | 低 | 插入类操作(如:订单创建、注册等) |
| 乐观锁 | 高 | 低 | 读多写少场景(如:余额更新) |
| 状态机 | 中 | 高 | 有状态流转(如:订单生命周期管理) |
| 分布式锁 | 高 | 中 | 强一致性(秒杀库存) |
思维导图
案例分析
幂等性失效导致重复提交表单问题
问题:高并发下,系统负载大,采用分布式锁实现幂等性时,在解锁到提交事务期间,其他线程获取到锁并提交事务。
结果:导致同一用户插入了两条相同的数据。
伪代码模拟:
1 |
|
在事务中,使用了 Redis 分布式锁。这个方法一旦执行,事务生效,接着就 Redis 分布式锁生效,代码执行完后,先释放 Redis 分布式锁,然后再提交事务数据,最后事务结束。在这个过程中,事务没有提交之前,分布式锁已经被释放, 导致分布式锁失效。
秒杀超卖问题
案例一:
1 | 加锁{ |
以线程A和B为例:
线程A得到锁,
线程A查看user表得到账户余额,,
线程A加上前端传来的余额,
线程A更新数据库。
开启事务
执行更新语句(注意此时程序顺序执行释放锁,线程B获取锁)
线程B获取锁,
查询user表获得未更新前的账户余额,
提交事务
线程B加上前端传来的余额,
线程B更新数据库。
案例二:
1 |
|
解决方案
方案一:加唯一索引
如果是表单重复提交场景,可以尝试给“订单号”等有唯一性的字段加唯一索引,这样重复提交时会因为唯一索引约束导致索引失效。
使用UNIQUE参数可以设置索引为唯一性索引,在创建唯一性索引时,限制该索引的值必须是唯一的,但允许有多个空值。在一张数据表里可以有多个唯一索引。
唯一约束和唯一索引的区别:
- 唯一约束和唯一索引,都可以实现列数据的唯一,列值可以有null。
- 创建唯一约束,会自动创建一个同名的唯一索引,该索引不能单独删除,删除约束会自动删除索引。唯一约束是通过唯一索引来实现数据的唯一。
- 创建一个唯一索引,这个索引就是独立,可以单独删除。
- 如果一个列上想有约束和索引,且两者可以单独的删除。可以先建唯一索引,再建同名的唯一约束。
- 如果表的一个字段,要作为另外一个表的外键,这个字段必须有唯一约束(或是主键),如果只是有唯一索引,就会报错。
方案二:事务外层加锁
- 分布式锁在controller层中添加,事务在service层中添加。
- 使用编程式事务,外层是锁,内层是事务。
方案三:嵌套事务
将查表更新表的操作单独封装成一个方法(在事务外面加锁)。然后加上spring事务(嵌套提交)。
1 |
|



